Years ago, a conference speaker pulled up a graph like this – video players all switching renditions at the same time for the wrong reason – and called the behavior “drunken teenagers”.

It stuck. I’ve been over-using it ever since – throwing it at every vaguely similar incident across platforms, to mostly confused looks. This is the explanation I never gave.
Your players are working exactly as configured
…and it’s usually the default config
As you grow, that may no longer be good enough. If it was ever good in the first place.
To name just a few ways it goes wrong:
- Error handling surfaces a generic message and stops – no retry, no fallback, no reload.
- Retry logic hammers the origin on a failed segment request instead of backing off.
- Players switch down on a single slow segment, not a trend – one bad measurement tanks the quality.
- The initial rendition is hardcoded, ignoring whatever bandwidth estimate the browser already has.
- Stall recovery drops to the lowest rendition and crawls back up too slowly.
- Time-to-first-frame inflated because the player preloads more than it needs.
- DVR window set too short – viewers who pause for two minutes come back to a dead stream.
- Heavy rendering or decoding blocks the video pipeline on low-end devices, causing stalls that look like network issues.
- Buffer sized for a lab connection. Stalls on the first 4G hiccup.
- Players preload the next segment in the background while the viewer is paused, burning data for no reason.
What the player actually does
The player buffers ahead. It picks a rendition. It decides what to do when things break. Three decisions, happening continuously, driven by config values you set once and forgot.
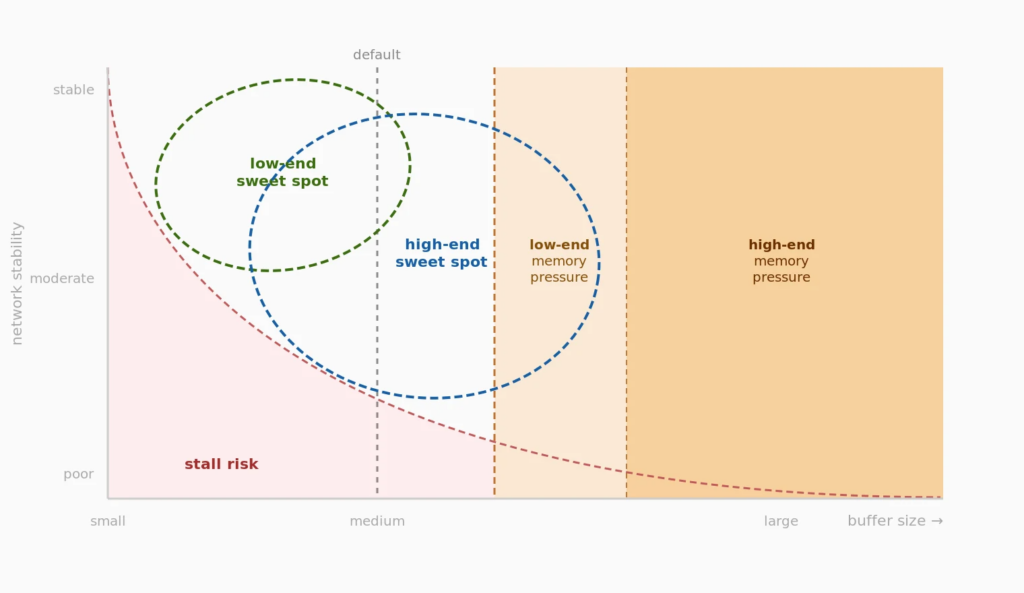
The buffer is how much video it preloads before it starts playing, and how much it tries to keep ahead. Too small and any jitter stalls the stream. Too large and you’ve added latency you didn’t need and memory pressure on cheap devices.
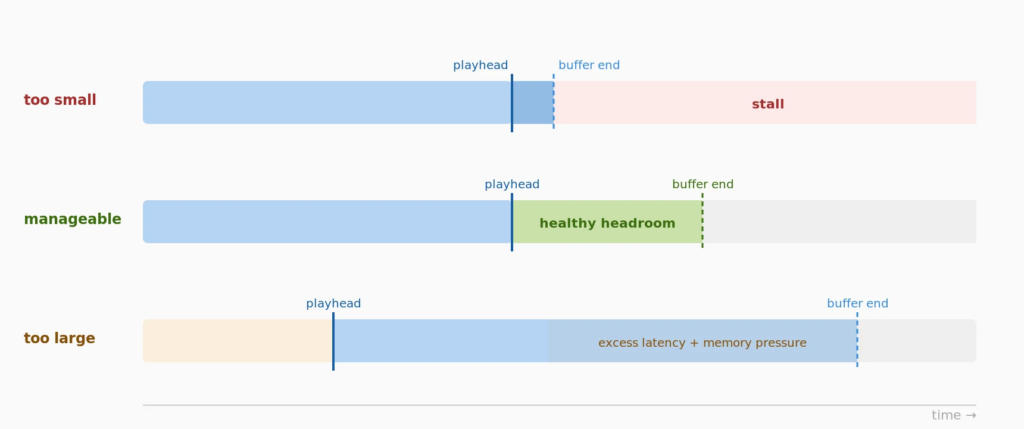
ABR picks the rendition. It estimates bandwidth from recent segment download times – a lagging indicator at best. On a degrading connection it’s optimistic too long. On a recovering one it’s cautious too long.
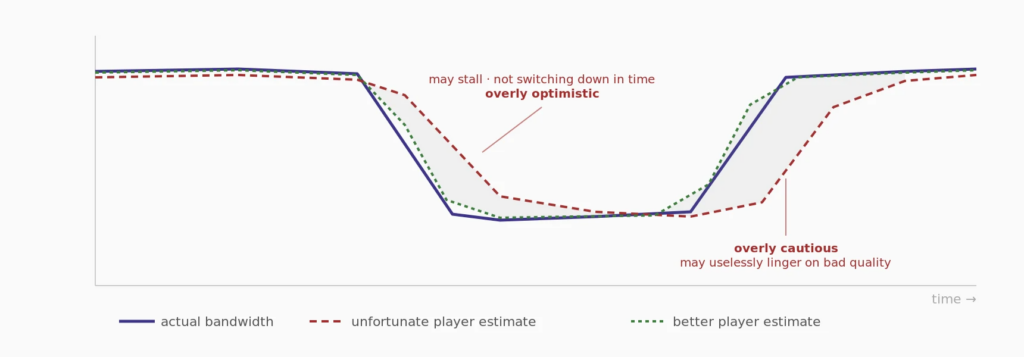
Stall recovery kicks in when the buffer runs dry. Drop to the lowest rendition and fill fast, or hold and wait. The wrong call compounds the problem.
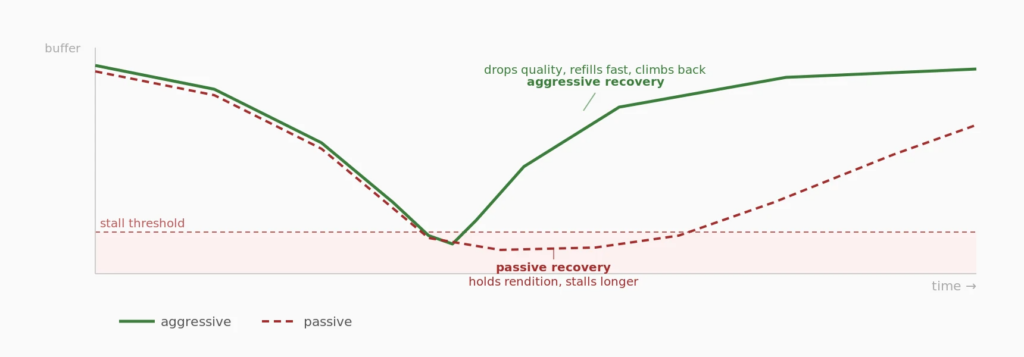
Wrong in many different ways
The default buffer is a single number applied to every viewer regardless of where they are, what they’re watching, or what device they’re on.
On a variable cellular connection, it’s too small. One hiccup and it empties. The stall isn’t a network failure. It’s a sizing failure.
On a live stream, it’s too large. Every second of buffer is a second of latency. A buffer sized for VOD puts live viewers that many seconds behind. The stream is technically live. The experience isn’t.
On a low-end device, it’s expensive. Buffered video sits in memory. Size the buffer for a flagship and you create memory pressure on the mid-range Android most of your viewers are actually using. That pressure causes frame drops. Frame drops look like network problems. The player reacts accordingly.
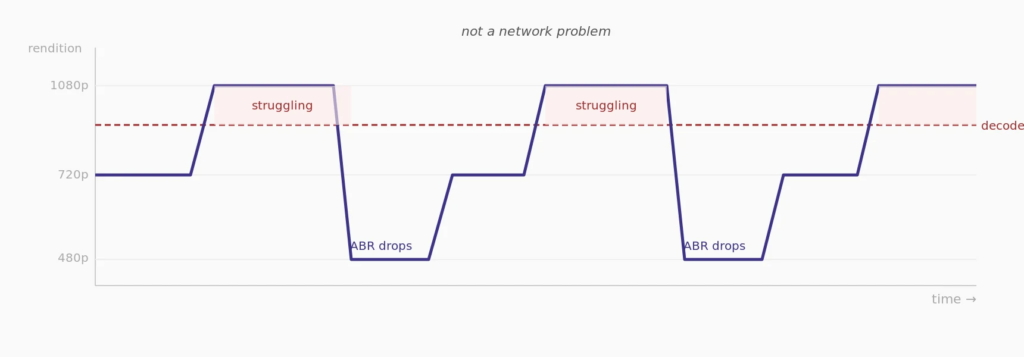
A stall isn’t always a network problem. On a low-end device, it can be a decoding problem.
Hardware decoders have caps. A budget Android from two years ago might handle 720p without issue and fall apart at 1080p – not because the network can’t deliver the data, but because the chip can’t process it fast enough. The player doesn’t (always) know the difference. It sees dropped frames, reads it as a buffer problem, and switches the rendition down.
That sounds like correct behavior. It isn’t. The player switched down on false signal. When the buffer refills, it tries to climb back up. The device struggles again. You get an oscillation loop that has nothing to do with network conditions.
When defaults become contagious
A cohort of viewers starts the same stream at roughly the same time. A few things align. They’re on the same CDN point of presence. Their segments are the same size. Their ABR algorithms are running the same evaluation on the same schedule. Something goes wrong – a CDN hiccup, a keyframe boundary that triggers a quality re-evaluation, a momentary spike in origin response time. Every player in that cohort hits it at the same moment and makes the same decision.
Rendition switches in lockstep. Stalls at the same second. Recovery in waves, because they all dropped to the lowest rendition simultaneously and are climbing back at the same rate.
Rendition layers cycling in near-sync. Players all moving together for no obvious network reason. That’s what drunken teenagers looks like at scale.

Not meant to defame teenagers. Not meant to encourage underage drinking.
What you’re not measuring
Your server-side dashboard shows nothing. CDN healthy. Encoder fine. Origin responding.
The problem is a JavaScript runtime on ten thousand devices making the same bad decision simultaneously, and nothing on your server can see it.
Stall events don’t exist in infrastructure logs.
They exist in the player. If you’re not instrumenting it and shipping those events somewhere, you have no visibility into the part of the stack that actually touches your viewers.
Most teams add player analytics after something breaks badly enough to notice.
By then you’re debugging from memory and user complaints. The signal was there the whole time, unlogged.
Player SDKs vary. Most expose stall count, stall duration, current rendition. Some give buffer level on a timer. Fewer give ABR decision events. Start with what you have. Something beats nothing.
The fix
This is a config problem. You don’t need to rewrite the player, swap the SDK, or file a ticket with your vendor. You need to read the defaults and decide if they make sense for your actual viewers.
Start with buffer size.
Pick a number for live and a different number for VOD. They have opposite requirements. One config for both is already wrong.
Test stall recovery deliberately.
Throttle the connection mid-stream. Pull the network. See what happens. Most teams have never done this and have no idea what their player does when the buffer empties. The default behavior is rarely what you’d choose if you’d seen it.
Test on a real device.
Not your laptop. Not Chrome DevTools throttling. A mid-range Android on 3G or 4G. That’s the device your median viewer is on. If it stalls there, you have a problem. If you’ve never tested there, you don’t know.
The config that ships is the config that runs. At scale, on every device, for every viewer. Treat it accordingly.
Scale makes it worse
At low viewer counts, bad player behavior is noise. One viewer stalls, another doesn’t. It averages out and you never see it in aggregate.
As the audience grows, the randomness collapses. More viewers starting at the same time. More players sharing the same CDN point of presence. More ABR algorithms running the same evaluation on the same segment. Individual failures synchronize into a pattern.
The misconfiguration that was a support ticket at a thousand viewers is a platform event at a hundred thousand.
And you’ll probably blame the CDN.