“Transcribe’s a penny a minute, just use it.”

Live captioning used to mean hiring a stenographer or wiring up a pricy cloud service. Whisper changed the second part. Transcription got cheap enough that the interesting question is no longer “can I afford captions” but “which way of paying for them is cheaper for my load.”
Your bill can come in 2 shapes:
Amazon Transcribe and metered services like it charge per minute of audio: roughly $0.024/min for streaming, which is $1.44 an hour per stream. The discounts don’t kick in until 250,000 minutes a month and only bottom out near $0.0078/min once you’re past five million.
The other shape is a GPU you rent by the hour and fill with Whisper: a g4dn.xlarge (T4) is $0.526/hr, a g5.xlarge (A10G) is $1.006/hr, and a RunPod 4090 hovers around $0.34/hr.
Those two numbers don’t compare directly, and that’s the whole point.
One bill is linear, the other is fixed
Transcribe costs the same per stream whether you run one or fifty. Ten concurrent channels cost ten times one channel. The price scales with usage, and there’s nothing you can engineer to bring it down.
A GPU costs what it costs whether you put one stream on it or twenty. faster-whisper running large-v3-turbo processes batch audio at 30-40x real time, and for live work you only need better than 1x per stream plus headroom. One mid-range card carries several concurrent caption streams; a 48GB L40S fits 25+ turbo instances in memory before it runs out of compute. The cost per stream is whatever you paid for the card divided by how many streams you managed to stuff onto it.
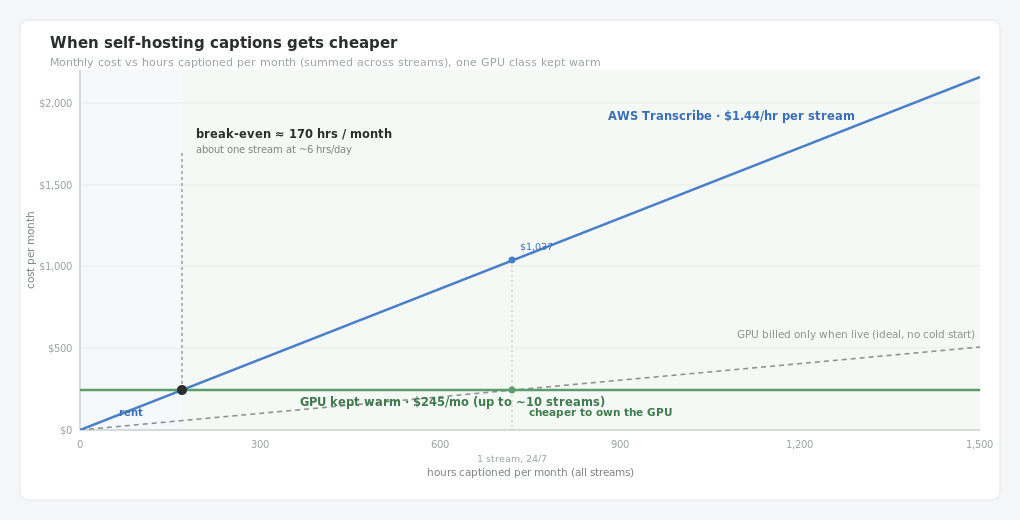
So the decision isn’t Whisper versus Transcribe on quality. It’s whether your load can fill a GPU.
One channel, around the clock
A single 24/7 channel on Transcribe is $1.44 x 720 hours, about $1,037 a month. The same channel on a rented 4090 at $0.34/hr is $245 a month, and the card is barely warm. Self-hosting already wins, roughly four to one, before you put a second stream on the box.
Ten channels, around the clock
Now Transcribe is ten times $1,037, about $10,370 a month. If those ten streams fit on one GPU, and a single strong card handles ten turbo streams, you’re still paying $245. That’s not a discount, it’s a different order of magnitude. The linear bill has run away while the fixed one hasn’t moved.
A three-hour event, once a week
Transcribe is three hours times $1.44, about $4.32 an event, with nothing to run, nothing to patch, and no idle. The GPU has to be spun up, loaded, and babysat for one stream a few hours a week. Here the per-minute bill is both cheaper and far less work. Renting the minute wins outright.
Run your own numbers
The three cases above are just points on a line. Drop in your stream count, hours per day, and GPU rate and find where you actually sit: [calculator].
Where the GPU math quietly leaks
Two costs don't show up in the headline rate.
The managed services bill wall-clock audio, silence included. A sparse channel, a webinar with long pauses, a lecture with a quiet room, still costs the full minute. Self-hosting with voice activity detection only spends compute on speech, so the gap widens further for talky, gappy content.
The GPU bills idle, and idle is hard to avoid for live. Scale-to-zero sounds like the answer, but loading a Whisper model takes tens of seconds, and a live stream can't wait for a cold start. You keep the card warm, which means you pay for the hours nobody is streaming. For spiky, unpredictable load that idle time is exactly what eats the supposed savings.
Is it worth it?
Below a handful of concurrent streams, or for bursty events you can't predict, rent the minute. Transcribe has no idle, no ops, and similar latency, and the bill stays small precisely because your usage is small. The per-minute model is built for exactly that.
Above a few steady, concurrent streams, own the GPU. A 24/7 operation with even a modest channel count crosses the line fast, and once you're filling the card the per-stream cost falls through the floor.
The crossover is concurrency times utilization, not stream count alone. Ten channels that each run an hour a day are a Transcribe job. One channel that never sleeps is closer to a self-host job than it looks.
How cheap is it, really?
At the bottom, a filled GPU gets you to single-digit dollars per stream-month, against roughly a thousand for the same stream on a metered service. But "filled" is load-bearing. An empty GPU is more expensive than Transcribe, not less, and it's yours to keep running.
Is it stable?
The managed service is. You hand it audio, it hands you text, and the failure modes are someone else's 4am alerts. Self-hosting puts three moving parts on you: the GPU, the streaming wrapper that turns a batch model into a live one, and the WebVTT packaging that aligns caption segments to your media segments. None of it is exotic, but it's yours to keep alive.
What's the catch?
Whisper isn't a streaming recognizer. It reads audio in windows and emits a transcript for the whole window, so live captioning leans on a wrapper like whisper_streaming, which only commits words once overlapping windows agree. That buys around 3.3 seconds of latency, tunable, and accuracy still slips on overlapping speakers, heavy accents, and niche vocabulary. The managed services sit in the same latency ballpark and need none of the plumbing. So the cost win has to clear the ops cost, and on a small or spiky load it usually doesn't.