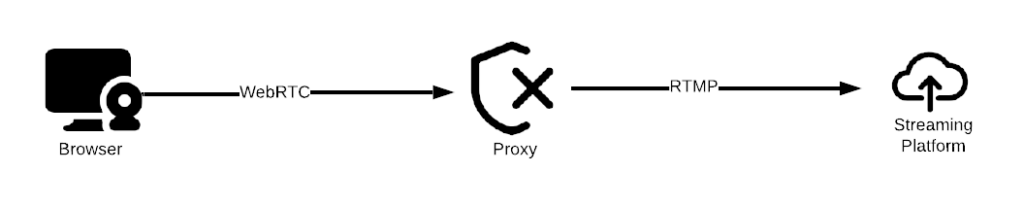
We did this before, but had to take down the solution after a client flipped the script unexpectedly. This time made sure it stays.
Try it first, talk later
But…
Sure, the browser isn’t pulling off any magic tricks – it still needs a proxy, just like last time. The tech is basically unchanged, so I’ll copy the picture from there and spare you the introduction. Most of the points in the original post are still valid, found another interesting read on the topic here.
What’s new?
WebRTC evolved marginally. Products supporting it, even less. The only slightly spectacular bit is the (relatively) widespread adoption of WHIP.
Browser support for H.264 in WebRTC is now standard and more reliable across major browsers, to the point where you no longer need to transcode it for RTMP. There’s also wide support for hardware accelerated encoding that browsers can take advantage via the system’s media frameworks (like Windows Media Foundation, macOS VideoToolbox, or Linux VA-API/VDPAU).
There’s pressure on RTMP’s dominance, as major platforms offer SRT ingest as an alternative. But it will be a long while before RTMP is out of the game. On the other hand, there are efforts to improve it to support newer codecs, HDR, multi-stream, better sync, reconnections/resilience, etc.
Why doing this again?
For a while we wanted to leave wowza’s WebRTC publishing solution behind as it’s unmaintained and lacking features. Previous iterations made use of Kurento and MediaSoup respectively; while there’s merit to both, they’re painfully inconsistent and not ready for production in some respect. Long story short, eventually decided to give OvenLiveKit a try and found that it works more often than it fails.
The polished solution
…is here, you can deploy it in minutes and adjust it to your linking.
Lessons learned
WHIP is good, custom is bad: we’ve seen the wheel (read ‘signaling’) reinvented so many times it started to hurt; it’s nevertheless funny we all came to agree that a common standard would be good, despite previously praising the openness of leaving it open to custom implementations.
Things can change: browsers still evolve and they may decide to alter the way WebRTC (or signaling) works in ways you don’t care to anticipate. Issues like this and that troubled some products so badly that workarounds had to be put in place before the maintainers of the (sometimes commercial) solution published a proper fix, sometimes months later.
Scaling audio transcoding remains the true bottleneck; planning for Opus -> AAC at scale is essential, while video transcoding can often be avoided.
Latency perception matters more than absolute numbers; users tolerate 2–3s RTMP delays if the WebRTC-to-proxy handoff stays consistent.
Expect complex configurations and developer friction: any WebRTC+RTMP pipeline is full of configuration pitfalls; certificate issues, codec settings, peer connection lifecycles, signaling race conditions, misconfigured ICE/STUN/TURN, neglected firewall rules – all introduce bugs and/or user frustration.
AV1 is a (fairly) new video codec created by a group of big tech giants including google, amazon, and microsoft, as part of some joint project. The main goal is to make video streaming better for everyone by offering:
Better Compression
Up to 30% better than HEVC or VP9, which is great for people with slow internet or limited data plans; just kidding 🙂, it’s greater for streaming platforms as they get to distribute the same content for cheaper
Royalty-Free
Unlike HEVC, which requires companies to pay license fees, AV1 is free to use. This makes it easier and cheaper for streaming services and device makers to adopt it.🙂
Yes it sounds a little too good to be true, and there are still some details worth keeping in mind. I’ll let you review the potential caveats for yourself:
It supports modern video features like 10-bit color, HDR, 8K+ resolution; to be fair, VP9 and HEVC support these too
Industry Support
Most major tech companies are backing AV1. YouTube, Netflix, and other big services are already using it for some videos, and new devices are starting to support AV1 playback.
Downsides
Hardware Support
Not all devices can play AV1 smoothly yet, especially older phones, TVs, or computers. Newer devices are adding support, but it will take time before AV1 is everywhere.
Encoding Speed
Creating AV1 videos (i.e. ‘encoding’) takes more compute power and time compared to older codecs. This is improving, but it’s still a challenge for live streaming or quick uploads.
Bottom Line
AV1 is a big step forward for online video. It’s already making a difference on some platforms, but it’s not the universal standard yet. As more devices and services support it, you’ll see faster loading, better quality, and less data usage when watching videos online.
The catch?
It’s only as good as the companies willing to adopt it. With luck, it becomes the standard… unless it gets shelved because it didn’t vibe with one’s golf schedule.
It’s commonly understood that ‘software encoding’ means encoding video on a general-purpose device and CPU. It is resource intensive but very flexible and easy to deploy.
Conversely, ‘hardware encoding’ requires specialized equipment. Rather than running complex algorithms, it makes use of dedicated chips to either do the whole encoding or offload the most critical jobs like motion estimation and entropy coding.
Without trying to be exhaustive, we’ll want to touch on the differences and trade-offs of one vs the other, promise it won’t take long:
Performance: given the same encoding settings, a hardware encoder will almost always be faster and more power efficient; that’s because components are designed specifically for such tasks, making the process highly economical
Flexibility: a hardware encoder can usually only output a specific subset of codecs and formats; logic of these has been ‘burned’ into the hardware and can’t be changed by rewriting software
Cost: the respective hardware needs purchased or rented upfront so it’ll be more expensive to hardware transcode at first; expect to break even and eventually have it pay for itself if you use it long enough
Form and size: devices vary much but expect hardware encoders to be smaller, slimmer, and more portable than their software counterparts
Reliability: every one device is different, yet hardware encoders are designed to run that specific job without interruption so they should crash less often
But wait, this piece is about transcoding, not encoding. I.e. the kind that you employ for adaptive bitrate, on the server/cloud, for a bunch of streams at the same time. And while the variety of consumer encoder devices way exceeds that of rack-mounted transcoders, there are still a few to choose from.
GPUs
…started to offer video encoding capabilities maybe 15 years ago. Lack of flexibility aside, the ability to offload the encode/transcode workload of a computer from CPU to GPU is very much welcome. That is, when it’s your computer and you’re broadcasting one stream towards Twitch or YouTube Live.
In a server environment the magic quickly fades. The coolest (i.e. most expensive) GPUs can encode 10+ streams at the same time; but that’s not their best asset, it’s just something they can also do. And since they’re also good for many other tasks (including crypto mining), their price matches the hardware complexity and demand.
Best implements I’ve seen will get you a 3-4 fold in transcoding capacity as compared to CPU, when stacking multiple GPUs in the same computer, yet the cost effectiveness of such implements is debatable.
FPGAs
…are devices that perform specialized tasks deeper in the hardware; in the case of video encoding, they can take performance to the next level both in terms of speed and number of streams they can process in parallel. As you can expect, they’re more expensive than GPUs but will eventually be worth it if you need to transcode a lot. And it’s these that Twitch itself transcodes on nowadays, along with Theo and many others.
Sure thing, it’s a whole different scenario if you
A. need to transcode a fixed number of streams 24/7
B. Your stream count fluctuates dramatically from day to night or during weekends
In the case of B. your mid-term investment in GPUs or FPGAs for transcoding could be wasted if you’re unable to fully utilize them. What if you could rent them by the minute instead? 🙂
Cloud Offerings
Yep, many of the clouds offer GPU equipped virtual (and real) servers, and lately AWS has instances equipped with video transcoding specialized FPGAs. And it’s these that we’ll try to squeeze the best ABR transcoding feat for the buck by maxing them out, hold tight.
What’s in the box?
The virtual server comes in 3 sizes, and bundled with the drivers and software to start experimenting right away. If you’re at least a bit handy with ffmpeg or gStreamer, it’ll feel like a charm. Take this one for a spin:
Cool, huh? In case I forgot to mention, there’s also a hardware decoder and a scaler in there so the above won’t use any CPU. At a glance, it flows like this
As you may see, the raw video (after decode and before re-encode) does not flow through your main computer’s pipeline (but through the FPGA’s) allowing for lower latencies than a common CPU transcode.
Going the extra mile
So we have a computer equipped with a high performance hardware transcoder. That transcoder itself has a limited number of streams and resolutions it can transcode at the same time.
However that FPGA physically lives in a computer with lots of CPU to waste. Can we use that to software transcode even more? 😈 Like this
Turns out that’s possible. Particularly the lower resolutions won’t take as big of a toll on the CPU so we can software transcode these and leave the big ones to the hardware. There’s a slight toll on the latency as raw video needs moved from the FPGA to the CPU pipeline, but let’s assume we can afford that.
The nugget
…is here. It spins up a cloud FPGA enabled virtual server and simply transcodes using the outlined technique. As compared to using just the dedicated hardware, it manages to transcode (up to, depending on use case):
25% more streams
56% more renditions
27% more pixels
…while paying nothing more. 😎
Does it scale?
The solution works best for a fixed number of live 24/7 well-known input streams. The main point of this research is to optimize cost, and running sensibly less than the supported number of streams on a given machine will compromise this goal.
Nevertheless, a scaling solution can be imagined by making use of autoscaling, load balancing (for RTMP ingress) and an ‘origin resolver’ similar to this.
Is it stable?
I see no good reason for it to be less stable than the hardware-only approach. Yet I never ran this in production. The thought of it struck me a couple years back while working on a large transcoding project, but it was not applicable there. Since, found no context to apply it, if anyone beats me to the game I’m waiting for feedback.
Does it fit my project?
By now, you probably have a sense of it, but if not, just give it a shot.
A quick heads-up, though: it won’t qualify if you use/require any of the following:
maximum resolution exceeding 4096 x 2160
very low latency – muxing alone (from 2 separate encoders) adds in excess of 100ms to the lag
user-generated content
some video profiles fail to decode accelerated
resolutions not multiple of 4 (width and height) are not supported
Ok, we’re peeking outside the box on this one. But hey, we all have to get into AI or get run by it, right? This post was written by a human.
Long story short, the client was looking for a novel approach to home (read hotel room) automation to impress the investors. It had to make extensive use of AI or it wouldn’t fly.
A couple hours of brainstorming later, we settled on a voice-driven solution that would allow users (read hotel guests) to manage the lights, curtains, and entertainment system, but also use as a friendly assistant for information or casual conversation, similar to ChatGPT.
The Constraints
This could not use a public service like OpenAI or Anthropic for multiple reasons, one of which being the need to ensure the privacy of user queries. The ability to deploy the entire GPT “brain” on-site (read hotel basement) was also a significant selling point. 😊
Furthermore, there needed to be strict control over which GPT model was utilized for specific deployments, along with the capability to introduce biases (political, religious, commercial) into some instances. Agree, that’s wildly controversial but for the scope of this story let’s see it as just another selling point.
Finally, it needed to be open source or at least not associated with the major industry players, allowing them to take pride in having developed their own solution.
Challenges
Hardware and Resource Demands
Running the voice-text-voice stack requires significant computational power, especially the speech recognition and (text) response generation. While GPUs are ideal for handling these demands, they aren’t always available in every environment. This makes optimizing systems for mixed hardware setups critical.
Balancing performance across varied infrastructure, whether with or without GPUs, involves careful tuning to maintain responsiveness and ensure the assistant works predictably even in resource-constrained scenarios.
Open-source Complexities
Going full open-source is like trading a smooth highway for a bumpy back road. These tools often require extra tinkering and development compared to polished commercial options.
Without the reliability and support of paid alternatives, teams must invest additional time in troubleshooting, integration, and ongoing refinement to ensure smooth operation and high performance.
Deployment and Scalability
Implementing this at scale poses challenges beyond computing power. As more users connect, maintaining seamless performance becomes increasingly complex. The system requires careful tuning to ensure efficiency and responsiveness, turning scalability into a juggling act.
In a self-hosted setup, you don’t have the flexibility of cloud-based scaling to adjust costs dynamically. However given the hotel environment, the occupancy is well known and that gives you a good idea of the maximum expected demand. This insight lets you cut down on infrastructure power during low occupancy times, making better use of resources and keeping things efficient.
Customization and bias
I won’t go into the ethics of it here. But technically, it can be challenging to determine how strong a bias can be before it becomes disruptive. Understanding how subtle biases affect user interactions requires careful analysis and testing to ensure a balance between effective customization and user experience.
And they agreed to make it public
Well, some of it.
Here is a refined version of the pitch that was presented to the investors, and they seem to have liked it. It’s fully stripped of the parts where you can control everything around you (lights, blinds, tv, room service, laundry, concierge) as they’re looking to patent portions of that.
Yet it’s a good starting point for any rookie AI endeavor. Since you can get it up and running it in some 20min, you’ll know sooner rather than later if it’s of any use for your project.
More challenges
Data Privacy and Security
Be careful with user voice data, as it could contain sensitive information. Encrypt everything in transit, securely store interaction history, and purge it upon checkout. However, if you aim to implement a “Welcome back, Mr. Anderson” things become more complex.
Model Optimization
Optimizing heavy AI models can be tricky, but it’s about making them faster and less demanding on resources. You can tweak them using techniques like compressing data (quantization), trimming unnecessary parts (pruning), or switching to smaller models that still get the job done. It’s all about finding ways to keep things running smoothly without losing too much accuracy.
Latency and User Experience
Reducing response times is essential for user satisfaction. One great feature of many models is their ability to start generating a response before the entire output is finalized. Similarly, when converting text to speech, you should begin generating audio as soon as text starts coming through, allowing for a smoother, more immediate experience.
Adaptation to Multilingual Settings
This is a topic in itself and there’s a lot to be said, but let’s try to stay on point.
The availability of English content far outweighs the others, thus English models are way better than any other.
Training on multilingual data will output a total mess, don’t do it
Translating to/from an English model is acceptable up to a point; you will lose coherence, sentiment, and idiomatic expressions that a native model might otherwise convey
In multicultural environments, users often switch between languages in conversation; handling mixed language input adds an extra layer of complexity to model training and deployment.
The agreed approach for the case in point was to just ask the user for the interaction language upfront, much like you see on flight entertainment systems. This keeps thigs simple and avoids traps. Native models are preferred but translations may be acceptable for some contexts. Extra languages can be added for particular implements.
Save face, use green energy
Sooner or later, customers and their customers become aware that this whole AI is power hungry. So we need to preemptively save them from the environmental guilt trip. Be sure to highlight that tech wizardry is being powered by renewable energy, or other eco-conscious practices you may implement.
User Trust and Transparency
You’ll want to be able to show what tech is in play and exactly how data’s handled—especially if the press or regulators come asking. Keeping things clear and upfront helps people feel secure about their data and builds trust all around.
Hallucinations
It’s happened to you already, I’m sure. A generative AI spitting out nonsensical, fabricated, or downright stupid content.
While models are slowly improving on this too, we kinda learned to live with it and use common sense and critical thinking (at least I like to hope that’s the case) when querying ChatGPT. But when a concierge voice bot confidently gets you on a cab to a restaurant that doesn’t exist, it becomes a problem.
To overcome this in the context, the provided solution sits on 3 pillars:
User Awareness – users are informed that the system may occasionally provide incorrect information.
Reporting Mechanism – users can easily report any inaccuracies they encounter.
Supervised Monitoring – supervisors monitor interactions to catch mistakes early, with their view filtered to protect user privacy
Will AI take over?
Eventually. But I wouldn’t worry just yet. At least 2 aspects seriously hold it back.
Data
Being smarter in itself doesn’t just make one more powerful. There’s only this much data that an AI can process, and that’s the whole human knowledge up until this point. But there’s no easy way for an AI to come up with new data and evolve fast enough to take us by surprise. Soon enough specialized AIs should be able to distill potential scientific, engineering, and artistic breakthroughs out of existing data. But these will be just ideas 💡 or concepts. Validating them into actual facts or usable new ‘data’ might still require good old experimentation, peer review, and some combination of imaginativeness and insanity that machines don’t yet possess.
Energy
If you manage to play with the demo, be curious of how intensive it is on the CPU or GPU while generating text for just one query. And that’s just one side of the coin, training a model takes great amounts of effort (read funding for infrastructure, energy, and human scrutiny). Otherwise, know that any GPT inquiry costs a few cents. If you’re getting it for free, it’s investor money.
While generative AI is the hype these days and where the money flows mostly, there’s way more to AI than that. The self-aware Skynet that we’re so afraid of will derive from something much more complex than a language model. And while the plot is not implausible, it’s hard to think such singularity would have enough leverage to highjack enough energy to sustain and grow itself, let alone build new power plants to keep growing and stay on top of human kind.
In the vast sea of video conferencing tools, each one carries its own set of quirks and surprises. Some go all-in on scalability, others nail simplicity, and a few hand you the keys for full customization — if you’re up for the challenge. To keep things lively, let’s break these down into some neat categories
Free vs paid vs freemium
Truly free
Either open source code that you can deploy on your own infrastructure (talk about these in a bit) or very simple hosted services. Truth be told, top notch video conferencing needs innovation and uses up resources, none of which are free. If it’s free for you it’s either because it’s crappy (i.e. reduced feature set) or somebody else is paying for it. Exaples: Jitsi Meet, MediaSoup, BigBlueButton, Talky, Briefing, Palava.tv
Freemium
If you’ve been on Zoom or Google meet a few times, you know what it’s like. Same product and mostly the same features for the free and paid, yet longer meetings and more participants/features for the latter. There’s also FreeConference, Microsoft Teams, GoToMeeting etc. These services are operated by major companies on their own infrastructure, so you’ll get good quality meetings even when using the free tier.
Paid
No free tier. They provide comprehensive features like advanced security, large-scale meetings, dedicated support, and deep integration with other business tools. They are geared toward enterprise-level use or large organizations. In this category: Microsoft Teams, Webex, BlueJeans, AnyMeeting, Connect, Dialpad, Adobe Connect etc
Open source or not?
Ok, the opensource ones are just code. It’s only after you deploy it on a server (or more) that it becomes a platform. Jitsi Meet, BigBlueButton, LiveKit, Apache OpenMeetings are all part of this pool. You can tailor them to your liking and fit them into custom workflows, but that can take a bit or a lot of work. Some are lacking features and many are not straightforward to scale.
In turn, most closed-source solutions are already established platforms. Think Zoom, Microsoft Teams, Discord, Cisco Webex, GoToMeeting – they all exist as entities that you just use, not software that you host somewhere. There are a few exceptions to this (Cisco Meeting Server, TrueConf Server), but they tend to cater to very specific niches.
Branded vs White Label
When setting up a platform, you have the option to either prominently display the Zoom logo and make it clear that you’re using their service for the conference, or alternatively, you can create a fully integrated experience that mirrors Zoom’s functionality but showcases only your branding, without any mention of Zoom itself. The choice to go with white label or not is about deciding between keeping control of your brand or going for something quicker and easier to customize.
The branded choices we already mentioned, white label solutions include Daily.co, Agora, Twilio, LiveKit, Pexip, TrueConf, Whereby
It is all WebRTC already?
Kinda. Though you can’t communicate through other means from a browser, in the realm of native apps some just use a browser wrapper while others actually make use of proprietary protocols for enhanced performance. I know, it’s a bit sad that WebRTC hasn’t quite become the magic bullet we were promised, and at this rate, we might be waiting a couple more decades for it to finally live up to the hype. Why so? Well, issues with standardization, leading to inconsistent browser support, combined with performance and stability challenges when scaling, and ongoing difficulties in managing latency and bandwidth, all of which make it hard to maintain a seamless experience across different networks and devices. It’s much easier to mitigate all these in the shadow of a proprietary protocol, especially if you’re a powerhouse like Zoom or Webex.
Why it’s hard to make videoconferencing flawless
For the most part, unpredictable unpredictable network connectivity. Not everyone has a connection fast enough to ingest the AV data others are pushing, may that be for the whole session or parts of it. When a slow user comes into the meeting, one of the following needs to happen
lower the quality for everyone (not cool)
find a way to send lower quality video to the slow user while still sending good quality video the others (cool)
Well the latter is complicated, requiring either serverside transcoding, SVC, or simulcast; coupled with complex logic to always be on the lookout for congestion and compensate; none of which are cheap, straightforward, or widely supported at the same time. And that’s where the big players make the difference – they can afford to pioneer and push the boundaries at higher costs and more sophisticated tech stack and infrastructure.
So what gives?
Among the many mentioned above, LiveKit stands a bit taller — and no, this isn’t a sponsored take! What sets it apart?
It’s fairily new, so it got to learn from others’ mistakes.
It’s open source, but without the fragmented progress seen in similar projects.
It’s still a commercial product, which allows it to finance fresh thinking; you pay if you want to use their infrastructure, otherwise you’re free to use yours
Ok, where’s the free conferencing platform?
Here. You can deploy it in a few minutes and play with it. If don’t have the few minutes, play with this first – it’s the hosted demo of what you can deploy on your own infrastructure and adjust to your liking.
Why bother?
If you just found out about LiveKit, it’ll help you bypass the steepest part of its (still lean) learning curve. As you now have it set up and working, you can move on to have it fit your context. Or just use it as is, the defaults are very well suited for real-world use.
Also, now that you’re hosting it yourself (at some cost), you can get a rough idea of how much of what you’re paying Zoom goes toward operating costs and how much might be profit, possibly funneled back into innovation.
Not least, you can now experience first hand how a top-notch open source app stacks up against its commercial counterparts and decide if the added cost is worth it.
Does it scale?
Glad you’ve asked. While the demo is a single-server take, LiveKit itself supports distributed setup.
But… there had to be a catch. When using the OS product, there’s a limit (think hundreds) to how many can join the same meeting, dictated by the capabilities of the servers you’re deploying it on and the stated fact that “a room must fit on a single node”. The (paid) hosted service does not have this limitation 😊
Is it secure?
It is. Checks all boxes you’d expect from a mature product, including end-to-end encryption.
How free* is it really?
Once again, you’re only paying for the infrastructure, i.e. the servers you’re hosting it on.
Budget 1¢/user/hour and take it from there. Your mileage will greatly vary with app specifics and users’ traffic patterns. LiveKit provides a benchmarking tool.
You’re at that point where your single-server or clustered streaming setup just can’t keep up with the spikes and you know for a fact that you need a CDN, kudos for getting this far. Or maybe you’re already using one but wondering if perhaps you’ve missed out on a better deal from the other guys.
Navigating public price offerings can be challenging. Between the assortment of parameters (ingress, egress, requests, transfer), hidden fees, offers too good to be true, temptation to give into long term commitments etc, one may find it’s quite tough to make a decision.
This piece will focus on comparing the true pay-as-you-go CDN vendors with public and transparent pricing models. By ‘true pay as you go’ I mean the flexibility to pay zero if you don’t use the service at all in a certain month. That’s important if you’re broadcasting occasionally (festivals, seasonal sporting events), or you just don’t know if your business will still be alive and kicking in a few months from now.
And here it gets graphed, comparing the few mainstream providers. Just adjust the ckecks and sliders to match your use case and make your pick, today.
Lessons learned
Stick with the big names
Unless you know your game really well that is. Smaller players will do their best to lure you into admittedly appealing deals, yet most of these will be either
(A) resellers – nothing wrong with that per se, except there may be a better offer from the very CDN they’re reselling; that’s not always the case, as they can negotiate better pricing than you ever could by leveraging big volumes and upfront commitments
(B) maintaining their own infrastructure – nothing wrong with that either, yet do expect inferior throughput due to the reduced footprint and peering capabilities; also they may run out of capacity when you need it most – at peak; sadly cards have been dealt in the industry more than a decade ago there’s no way to stand up to the giants unless you’re a giant yourself
(C) hybrid – relying on both own and 3rd party infrastructure and trying to make the best of each; that’s admirable, still… they need to walk a fine line prioritizing either quality or profit, as it’ll be very tempting to try max out the (usually) inferior inbuilt capacity before racking up the upstream bill
(D) tricksters – still sharing traits with one of the above categories, yet at the very dishonest end of the scale; expect generally poor quality for the buck, slowdowns, interruptions, being throttled in favor of other customers, untruthful traffic measurements
Not meaning to scare you off, and there are surely exceptions; you’ll be able to find gold if you take the time to dig, especially among the local providers.
Always have a backup
There are many ways a network can fail, get saturated, or otherwise work against your best interest. Be prepared to switch or offload to some other vendor, may it be more expensive. There’s no good excuse for not being able to deliver the service you promised, and the chance to earn back the trust after a big fail may not come easy, if at all.
Where you deliver matters
While North America and Europe are well covered, providing fast connectivity elsewhere is often not straightforward.
Geographical regions discussed are those offered commonly by all suppliers. Yet some will cater distinctly to destinations like Africa, Middle East, India, Japan etc. You need to do a more in depth research if you focus anywhere there, look into local dealers too.
What goes into the graphs and what doesn’t?
The per-GB egress price – this makes the bulk of the pricing. Varies between $0.02 and $0.466, depending on region and consumption (i.e. the more you use the less you pay per unit)
The per-request price – varies between $0.6 and $2.2 per million HTTPS requests depending on region and offering. HTTP requests are cheaper with AWS but have not been considered here.
The per-GB ingress price (aka cache fill), where applicable – varies between $0.01 and $0.04 depending on ingress and egress location, only applied to google’s offering
The somewhat hidden $0.075 per hour for google’s ‘forwarding rule’ – a must-have paid-for link in their CDN chain.
The licensing price for a month in the case of Wowza
What about Akamai, CloudFlare, Comcast, Fastly, Level3, LimeLight etc
They don’t have public pricing, so we won’t discuss them here. Also some will require commitments and/or longer term contracts to have you as a customer. That does make sense for a company that offers this as its main service, as they need to rely on a somewhat predictable income to invest in capacity.
Do realize that there’s reselling (explicit or not) even at the highest levels, Azure and Wowza among them.
Can I use more than one?
Most certainly can, and you should if it’s feasible. Also know how much you’re paying each for exactly what, and over time use the information as leverage for a possible better deal. And stay on the lookout, the market continuously evolves and all this may be obsolete in a few months.
Since we last brought up the topic, the industry has evolved a bit. Most of the big live streaming and social media players now routinely stream at under 5 seconds end-to-end latency, and your modest platform may be laughed at or lose business if still relying on the good old HLS/DASH and its inbuilt huge delays.
The technological background hasn’t changed much, yet the emergence of ‘cord cutting’ has emphasized on the annoyingly big delays and pushed OTT providers to adapt and innovate. Where it could, LL-DASH has been implemented with relative success, periscope’s LHLS has had (and still has) its own success stories, and eventually apple had to step into the game and put together its own LL-HLS, currently already a published standard and deployed in the latest iOS.
As we speak, there are a few factors at play that may set back your roadmap to low latency
Support for proprietary WebSocket based streaming is going away, most notable possibly being wowza’s announcement to discontinue its ‘ultra low latency’ thing; it makes sense in light of market-driven evolution of alternatives and fact that this was a stand-in solution from the get-go, with obvious drawbacks
WebRTC is not yet a grownup; while having been standardized and taken a giant step since available in Safari, remarkable implements are taking a while
Player and server support of LL-HLS is still limited to commercial products
LL-DASH support is still not ubiquitous
The treat
To the rescue, a friendly wrapped POC solution based on the rather amazing open source OvenMediaEngine. It supports both WebRTC and LL-DASH egress from a RTMP source, amongst other cool stuff.
The WebRTC output lets you stream with sub-second latencies (!), and the LL-DASH can be configured to use a playback buffer of 1 second or less.
As long as you can deploy/make use of reverse proxies that support chunked-transfer, scaling is a breeze. Nginx can do it, as do most CDNs – go for it.
The larger shortcoming of WebRTC is that it’s been designed for peer-to-peer and one-to-one; twisting it to support one-to-many means impersonating multiple one-to-one endpoints, each mildly resource consuming, to the point where it’ll choke any one server.
Capabilities will largely vary depending on actual hardware, and stream characteristics. Consider just 200 viewers per cpu core when budgeting, any betterment will make your customer happy.
There’s also the hot topic of transcoding. While AVC is (at long last) ubiquitous in WebRTC, you’ll need to transcode the audio to Opus. That’s surely a breeze for any CPU but it won’t scale, so the number of streams you can run on a server is limited.
Is it worth it?
If you absolutely need cheap/free low latency, it is.
Biggest conundrum being that DASH won’t work on iOS and WebRTC is harder/more expensive to scale, may I suggest you use both (have iOS users play the WebRTC feed) and see where your scalability needs take you. Provided you’re running a small/medium platform or just starting up, the odds are you’re better off than giving into commercial offerings.
What about LL-HLS?
In OvenMedia, it’s reportedly in the works and may be available soon. In general, it may still be a while before we see it thriving. Partly due to its initial intent to mandate HTTP/2, the industry has been slow to adopt it, and the couple implements I’ve seen still get laggy provided near-perfect networking and encoding setups.
Adaptive bitrate anyone?
Not supported with this product but it may soon be.
Let me point out though that the two (ABR and extremely low latency) don’t go particularly well together. Think that
The need to transcode for ABR will add to the latency
Determining network capabilities and switching between ABR renditions is way tougher to properly plan ahead and execute given sub-second delays and buffers
In the big picture, you’re trading every second of latency for quality of experience or cost. Please don’t make it a whim and seriously assess how bad and how low you absolutely need it. Delivering near-instant high quality uninterrupted video over the open internet requires sophisticated/expensive tech, and even the most state of the art won’t deliver flawlessly to all.
You’ve seen it around on big guys’ platforms. But when trying to put together your own you may have hit the price, maintenance, or scalability wall.
The following solution is no magic fix to these and surely not special, yet it may help you understand the pitfalls and tell apart the clues ahead of time.
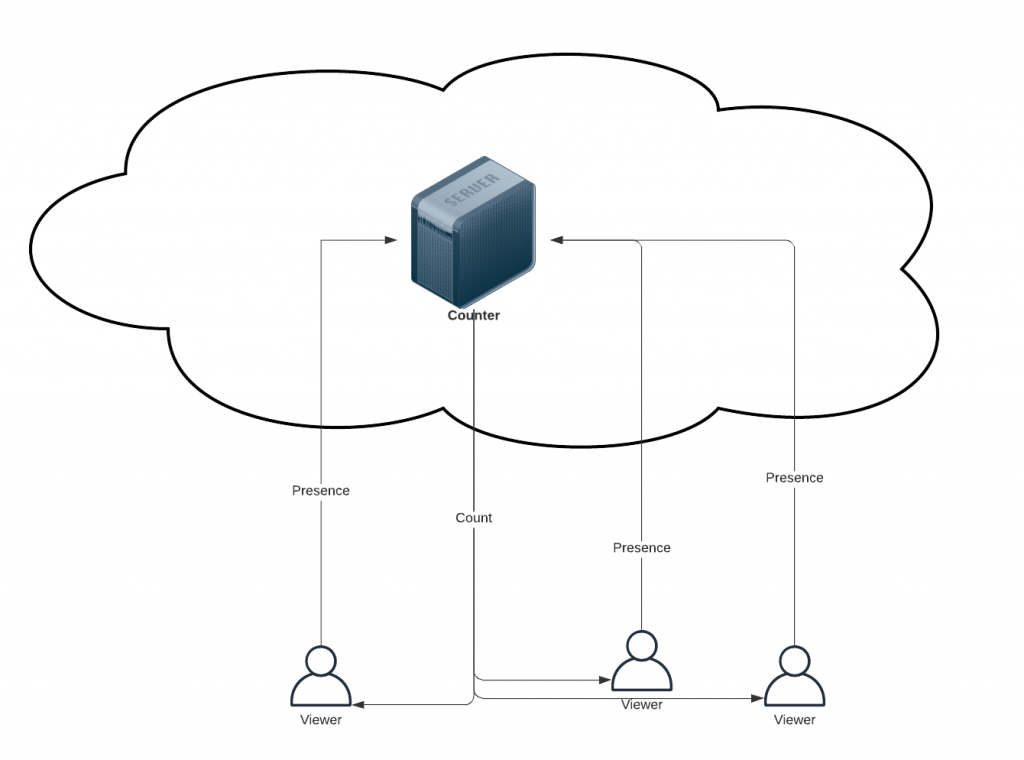
How it works
As simple as you’d imagine. Each viewer announces its presence to a central authority, let’s call that the counter. As soon one new such presence is announced, all the viewers are notified that the audience count has increased. Also, as soon as any viewer disengages, the others get notified that the respective count decreased.
Persistent connection
To facilitate instant updates, a continuously open connection is required between any one viewer and the centralized counter. Having the former just ask around for the number every once in a while (i.e. polling) is still an option but won’t be nearly as smooth or fast.
Sockets
Such connectivity can generally be accomplished by means of sockets. Long story short, a socket is a kind of nearly-instant bi-directional data channel between 2 network-connected devices.
WebSockets
Many most apps are commonly able to liberally create and make use of regular sockets, however the restrictive context of an internet browser cannot. Special abstractions had to be figured to bring socket-like functionality to the browser, of which the WebSocket has surfaced and is finally widely supported.
The server
The so called counter is merely a piece of software; it has to reside on a publicly accessible, always-on computer or device that oldsters like to call a server; while it does a lot of things, a server’s main job is to ‘serve’ common needs of various other (not necessarily so public or available) devices, generally referred to as ‘clients’.
The ready to use solution
Is here for grabs. Variations have been implemented on multiple platforms and it’s stood the test of time.
How cheap is it?
You’ll just be paying for the ‘server/s’. Unless you can run the counter on one of your existing computers [remember it needs to be public] or take advantage of some cloud’s free tier (in which case it’s free, as in beer).
In production, consider budgeting $1 per 1k simultaneous viewers per month, prorated.
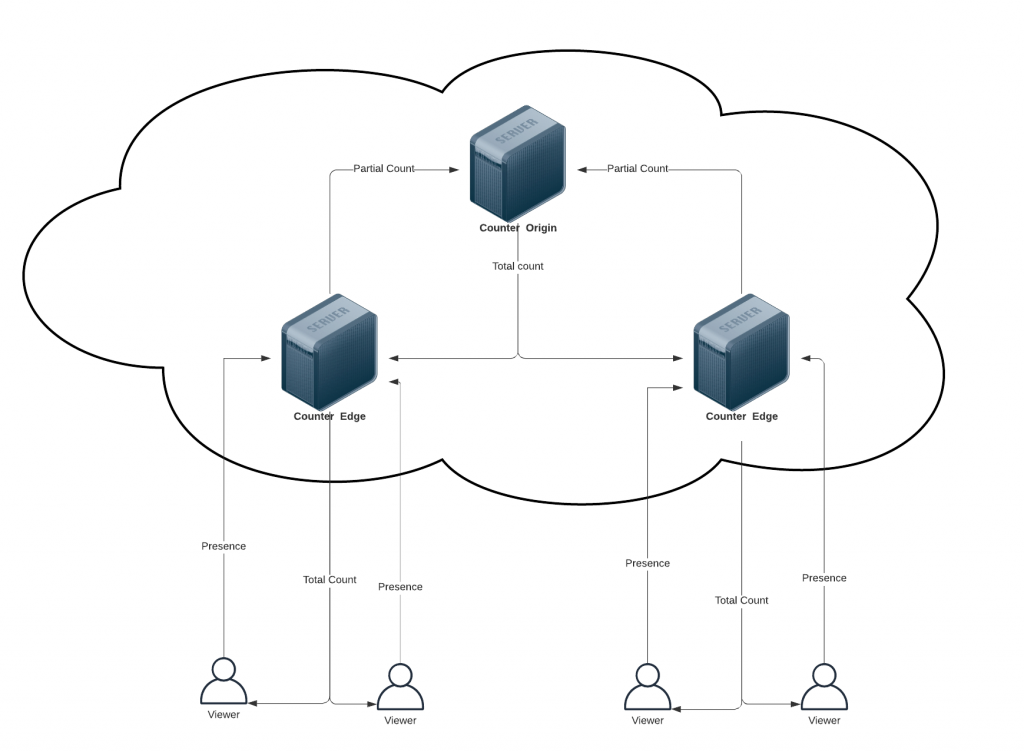
Does it scale?
Not without headaches.
The boxed solution is well optimized and proven to accommodate some 10k viewers when running onto the smallest available cloud instance (with just 0.5 GB of RAM!)
It can stretch to take up to maybe 4-5 times that much on a single computer but the truly scalable setup takes an autoscaled cluster of ‘servers’. Not too complex really, it has been done a repeatedly and hope to get the time to dust one up and make it public soon.
Is it stable/reliable?
Up to a point…
You’ll see it hogging the host’s CPU way before it starts being laggy to your viewers. Run it on a more powerful computer next time you expect a similar or larger audience
Memory use hasn’t been a real concern in any of the implements
If noticing a rather constant limit your counter never goes above, your setup (either the software, OS or NIC) may be running out of sockets it can simultaneously keep open. There are many ways to mitigate that, details vary with specifics of the environment
Before WebSockets were ubiquitous, long-polling (and at times its creepier cousin short-polling) was the norm for setting up persistency in the browser; these put a more severe burden on the server and are safe to be avoided, at long last; don’t give in to the likes of socket.io unless you really know what you’re doing
Is it secure?
In the example it’s not. Meaning that if one wanted to impersonate extra viewers into your pool they could easily do so. Also go the (DoS) extra mile and try to bring the ‘counter’ and the server hosting it to its knees, by impersonating a jolly bunch of extra viewers.
Not to say it can’t be made safe. CORS and SSL are the first things to consider. Also some simple way to limit rate and payload size.
Next up, any extra validation, authentication, tokenization etc. will take a slight toll on the server resources, multiplied by one of the numbers above. So be wary and benchmark each addition.
Is it fast?
Yesss! As fast as you’d expect an update to propagate over the internet these days, at half the speed of light if lucky.
Sounds like a simple task, why is it so hard to scale?
Think the following scenario: 100 average viewers, each coming in or out every 10 minutes. That’s 10 updates per minute, to propagate to all of the 100, for a total of 1000 updates per minute.
Now for 1000 average viewers, each also coming in or out every 10 minutes. That’s 100 updates per minute, to propagate to all of the 1000, for a total of 100k updates per minute.
Take that for 10k average viewers, it’ll be 10M (!) updates per minute. And that’s just averages, real life will show you that the audience tends to flock in the beginning and key moments of an event.
Ok, there are tricks to smooth out the treacherous exponential there, and you know one of them already. Display 1.7k viewers instead of 1745 viewers. That’s a hundred-fold reduction in the number of updates, out of the box! And there’s more to be done of course.
There’s a shred of misunderstanding, to say the least, when it comes to grasping and facing the codecs licensing topic. General perception being that if you’re just starting out you don’t need to worry about it, the warning here is that it may crawl up on you as you grow, depending on how you put that codec to good use and especially how you monetize it. Let’s start with the basics though.
Intellectual Property
Many video compression techniques included in a codec are patented inventions. To use the codec, you’d have to license the patents from their creator or representative. Fair enough, except we are talking about a few thousand patents from a few dozen companies.
To simplify licensing, copyright holders ‘pooled’ the patents through organizations that sell these collectively on behalf of their members.
While there’s more than a single pool, and some patents are unaffiliated, it is commonly agreed that you only need to reach out to MPEG-LA to license H.264 (aka AVC), while in the case of H.265 (aka HEVC) you need to pay at least the 3 big pools (MPEG-LA, HEVC Advance, Velos), of which the latter does not even publicly disclose prices.
Known pricing
Terms under which a license is sold are rather complex and highly nuanced. Cost will vary depending on the context respective codec is being used, volume, and revenue you may drive from it.
Very much notable, some use cases bear no cost, while others carry a generous entry level threshold. Nevertheless, do pay attention, and let’s take these one by one.
Per-Device
Applies to smartphones, tablets, digital and smart TVs, computers, video players and anything with a hardware encoder or decoder of the respective codec. Royalties are owned by the device supplier and not by the encoding/decoding chip or module manufacturer.
Also applies to software products that include an encoder or decoder. Royalty is owned by the product vendor/distributor, whether the product itself is commercial or free. Notable exception: free products (truly free, like Firefox) may include the OpenH264 binary, in which case royalties will be generously covered by Cisco.
Per-Title PPV
These include platforms that sell access to content on a per-title basis. Royalties are either (A) a fixed value per sale or (B) a percent from sales to end-users, in some cases the lesser of the two. Note that tiles (i.e. videos) 12 minutes or less are exempt from such royalties.
Subscription-Based PPV
Royalties apply to subscription platforms like Netflix and vary depending on codec and number of subscribers. There’s a zero cost entry level for AVC if one has less than 100K subscribers.
Free Television Broadcast
Applies to terrestrial, cable and satellite broadcasters, with pricing per encoder or size of the audience
Free Internet Broadcast
You own no royalties if encoding content to be distributed for free over the internet.
Real world (small) business models, and how much they may own
Mobile apps
We’re obviously talking about mobile apps that either play or broadcast/manipulate video through either one of these codecs.
If you rely on a hardware or OS exposed encoder/decoder to do the job, you don’t owe anybody anything, godspeed!
If you include a software encoder or decoder in your app, you fit into the ‘Per-Device’ category. For AVC you don’t pay anything until you reach 100K units (i.e. actively installed apps).
For HEVC, you’ll be paying from the ground up, think $1.5 to $4 per unit.
Streaming platforms
You owe royalties if you distribute AVC or HEVC encoded content, unless it’s free as in YouTube.
A TVOD platform (or the live streaming pay-per-title equivalent) should pay MPEG-LA 2¢ or 2% per title sale for H264 and/or 2.5¢ to HEVC Advance for H265. There is no entry level freebie for this model.
A SVOD platform (or the live streaming subscription-based equivalent) starts owing MPEG-LA between $25-100K for AVC after they go over 100K paying customers. HEVC is not as friendly to newcomers and you owe HEVC Advance ¢0.5-2.5 per customer from day one.
Cloud encoding
If you operate a service that sells the encoding/transcoding service explicitly (like encoding.com does), you definitely do owe royalties. How you will be billed is however rather uncertain. You’ll ultimately have to reach out to licensors and ask, I have at least 2 customers being charged very differently for quite similar business models. Common sense would even so dictate that
If you charge for encoding by the item (title) you will pay royalties per title
If you charge for encoding via a subscription, you will fit into the subscription-based royalty model
If you charge for encoding by the minute, you may (possibly) fit into the per-device category, where each encoding server counts as one such device
If you transcode video internally, as part of a larger streaming platform, there’s no clear rule/guideline on how licensing works and you also have to ask. A couple customer stories would lead yours truly to believe that
If the platform distributes paid content (SVOD or TVOD) and already paying per-title or per-subscription royalties in that respect, there is no extra charge for the encoding part
If the platform distributes free or AVOD content, it may owe per device (i.e. transcoding server or server core/thread) royalties; or it may not 😐
Online TV Stations
If it’s free to watch, you’re in the clear, no royalties.
If it’s a paid service (i.e. subscription) you do owe it. Even if streaming is powered by a 3rd party platform and/or commercial player, the organization that labels the content also has to license the technology. Now you know.
Will They Come After Me?
Possibly not. Interesting enough, the ‘pool’ organizations cannot and do not deal with litigation.
Never heard of any small player being anywhere close to indicted but still…
As your startup begins to grow, you should start being aware of how much you owe and consider that you might someday need to pay it all retroactively. Balance your encoding needs and don’t shoot for the mightiest codec unless you really need it. Explore alternatives and know your options.
Are there free alternatives?
Sure!
AV1 is everyone’s dream: royalty free, and backed by an alliance of 48+ members; but it’s rather new, half baked, and it will probably be long before you’ll find a decoder for it in every device out there; but definitely one to look after in the years to come.
VP8 and VP9 are roughly comparable in quality to AVC and HEVC respectively, and also royalty free; except they’re only supported by google. While they admirably carried out the complex (and expensive) job of bringing these to market and safeguarding them from patent claims, they failed to convince the other big boys to adopt it; so hardware support is still scarce some 10 years later.
Where to go next?
See Jina’s article on the matter of AVC licensing, it may help clear out extra concerns. Also a couple of great articles here and there.
Perhaps you should. More so if you’re annoyed at the inconsistent latency of RTMP, dealing with packet loss over RTP/RTSP or tired of running long SDI or HDMI cables.
Although rather different, these 2 share common traits, possible reason they’re sometimes discussed together or confused among. They’re both designed for low latency video transmission, both came around in an attempt to fill a gap in existing technology, they’re free and widely adopted. And the similarities stop here.
Internet vs LAN
By design, SRT is intended to transport video via the open internet and other unpredictable (i.e. prone to bandwidth jitter and packet loss) networks. In turn, NDI works at full potential over consistently fast (read Gigabit or better) internal networks that can guarantee extremely low transmission error and congestion rates.
UDP vs TCP
You know already, TCP is fully reliable while UDP is not. The former will retransmit lost packets until successfully delivered, the latter will just let them get lost and not retransmit anything. Retransmission introduces delays, and the frequency and length of these delays is unpredictable.
SRT runs on top of UDP, NDI runs on top of TCP; NDI is arguably faster than SRT. Wait, what?
Latency
SRT allows you to set a fixed latency (120ms by default) for your video transmission. It will retransmit the packets that were lost over UDP only if not too late to stay within that latency margin. Depending on the speed and quality of the network between the 2 endpoints, setting a slightly higher latency may visibly reduce the amount of video and audio ‘glitches’ caused by undelivered packets.
NDI advertises near-zero latency. It however demands a very fast and non-jittery network, or it’ll degrade ungracefully. Fact that it rides over TCP is therefore rather irrelevant as the low latency is only achievable if the packet loss and retransmission are minimal.
Encoding
SRT is allegedly codec and format agnostic and only takes care of transporting video payloads across the network. There’s room for debate but let’s just mention that most of the tried and true implements gracefully deal with AVC and HEVC wrapped in MPEG-TS.
NDI manages both encoding, transport and decoding, thus it takes and outputs raw video. Internally a subset of H264 is used, more often than not trying to take advantage of built-in hardware encoders and decoders on host devices.
Video Quality
In the case of SRT, what you send is what you get. If it’s not well tuned with the network capabilities (or if these degrade beyond ordinary) you’ll see or hear the ‘jerks’ commonly associated with packet loss.
NDI is so called ‘visually lossless’, meaning the encoding artifacts will be virtually unobservable by the naked eye. Surely at the expense of…
Bandwidth Consumption
For NDI, it’s huge; think 100-150Mbps for a full HD stream and at least double that much for 4K.
With SRT, it’s up to you, as you’d need to figure out how to encode and mux the video before sending it off to transport. Do take into account the overhead introduced by retransmissions, especially if your network is busy.
Can I play with it?
Sure can! Put together a simple low latency streaming platform proof of concept. Based on Nimble (hey, it’s still free, wowza more than tripled their price over the last few), featuring SRT ingress and SLDP egress, you can deploy it in a few clicks and test it in a few minutes. It’s a mere adapt/simplification of the earlier larger scalable low latency project.
Fine, I’m interested, which best suits my use case?
Let’s recap the differences, and this time bring our old friend RTMP into the mix, should help make an educated choice
RTMP
SRT
NDI
Designed for
Streaming over Internet
Streaming over Internet
Streaming in LAN
Transport
TCP
UDP
TCP
Latency
Higher, Unpredictable
Low, Customizable
Lowest
Signal Quality
High
Good
Nearly Lossless
Deals with
Transport
Transport
Encode and Transport
Bandwidth consumption
Encoding Dependant
Encoding Dependant
High
Are they expensive?
They’re both free, although NDI is proprietary yet royalty free, while SRT is fully open.
Are they secure?
SRT supports AES encryption.
NDI has no built in encryption mechanism afaik, if that’s critical you can run it over a VPN of some kind.